论文链接:https://arxiv.org/pdf/2506.09033
代码链接:https://github.com/ulab-uiuc/Router-R1
摘要
各种大语言模型 (LLM) 的迅速涌现,推动了 LLM 路由器的发展,这些路由器能够将用户问题分配给最合适的模型。然而,现有的 LLM 路由器通常执行单轮一对一映射(即将每个问题单独分配给单个模型),这限制了它们处理需要多个 LLM 互补优势的复杂任务的能力。本文提出了 Router-R1,这是一个基于强化学习 (RL) 的框架,它将多 LLM 的路由和聚合构建为一个顺序决策过程。Router-R1 将路由器本身实例化为一个功能强大的 LLM,利用其推理能力将“思考”操作(内部审议)与“路由”操作(动态模型调用)交织在一起,并将每个响应集成到其不断发展的上下文中。为了促进学习,我们采用了一种轻量级的基于规则的奖赏机制,该机制包含格式奖赏、最终结果奖赏和一种新的成本奖赏,用于优化性能和成本之间的平衡,从而开辟了一条通过强化学习来增强性能与成本权衡的途径。 Router-R1 还仅以简单的模型描述符(例如定价、延迟和示例性能)作为条件,从而能够强泛化到未见过的模型选择。在七个通用和多跳 QA 基准测试上的实验表明,Router-R1 的表现优于多个强大的基准测试,在保持稳健的泛化能力和成本管理的同时,实现了卓越的性能。
1.介绍
大语言模型 (LLM) 以前所未有的速度激增,新的架构和经过微调的变体每月甚至每周都会发布。为了充分利用多个 LLM 的互补优势(例如,一个模型的流畅性与另一个模型的事实准确性),LLM 路由器已成为关键的基础设施组件,它可以动态地将用户问题分派到单个选定的模型,以最大限度地提高答案质量和效率。虽然这种一次性路由策略可以提高平均性能,但它忽略了一个事实:真正复杂的推理任务通常需要多个模型之间的协调交互,不仅要协调单个选择,还要协调一系列模型调用,以充分利用它们的互补优势。这一观察提出了一个关键挑战:如何在多轮路由和聚合过程中协调多个 LLM,共同解决复杂任务?
应对这一挑战并非易事。首先,选择每轮调用哪个LLM的离散决策过程本质上是不可微的,这阻碍了通过反向传播进行直接的端到端训练。尽管先前的研究已将基于梯度的方法应用于单次路由,但将其扩展到多轮选择和聚合很快就会变得难以处理。其次,现有的路由器采用单步运行模式:给定一个查询,选择一个模型,收集其输出,然后停止。然而,复杂的任务(例如,多跳问答)需要一系列交错的推理和模型选择决策,而一次性的选择很少能满足需求。因此,我们必须设计一种相互作用机制,在“长思考”推理(内部思考)和有针对性的LLM选择之间交替进行,以迭代地完善答案。
为了应对这些挑战,我们引入了 Router-R1,这是一个基于强化学习的多轮 LLM 路由和聚合框架。我们并非做出单一的调度决策,而是将 LLM 协调表述为一个序列决策问题。在每一步中,Router-R1 都会选择执行内部推理(“思考”),还是从可用的 LLM 池中调用特定模型(“路由”),并通过迭代交互逐步构建答案。为了支持推理和路由之间的这种相互作用,我们将路由器本身实例化为一个功能强大的 LLM,利用其固有的推理能力进行长上下文审议和有针对性的模型选择。这种灵活的推理和模型选择交织使 Router-R1 能够以任务感知的方式自适应地组合多个 LLM 的优势。为了优化这一决策策略,我们采用强化学习,并设计了一个简单而有效的基于规则的奖赏函数,该函数由三部分组成:用于生成结构良好输出的格式奖赏、基于任务正确性的最终结果奖赏,以及用于惩罚过度使用昂贵路由模型的成本奖赏,从而使 Router-R1 能够在训练过程中权衡性能与成本。此外,Router-R1 通过根据价格、延迟和示例性能等简单描述符来调整其路由决策,无需重新训练,即可对新增的 LLM 候选模型展现出强大的泛化能力。这些组件共同构成了 Router-R1 一个强大而灵活的解决方案,可用于协调多个 LLM 来解决复杂的推理任务。通过在七个不同的 QA 基准测试(涵盖通用问答和多跳问答)上进行全面实验,我们证明 Router-R1 的表现始终优于多个强大的基准测试,并达到了最佳性能。对成本感知路由和对未知 LLM 泛化的进一步分析也凸显了我们方法的灵活性和稳健性。
我们的贡献总结如下:
- 我们提出了 Router-R1,一个基于强化学习的多轮 LLM 路由和聚合框架。通过将路由器本身实例化为一个功能强大的 LLM,Router-R1 可以自然地交织内部推理和外部模型选择,从而实现跨多个 LLM 的自适应协调,以解决复杂的任务。
- 我们设计了一个简单有效的基于规则的奖赏函数,该函数由格式奖赏、最终结果奖赏和成本奖赏组成,使 Router-R1 能够权衡性能与成本。此外,通过以简单的模型描述符为条件,Router-R1 无需重新训练即可推广到未见过的 LLM。
- 通过对七个问答基准进行大量实验,我们表明 Router-R1 优于几个竞争基线,实现了卓越的性能和强大的泛化。
2.Related Work
2.1 Query-based Routers for LLM Selection
各种LLM的迅速崛起,推动了基于问题的 LLM 路由器的发展,旨在将问题引导至最合适的模型,以提高响应质量和效率。HybridLLM 提出了一种动态路由器,可根据预测的查询难度和用户定义的质量预算,在小型和大型LLM之间进行选择。GraphRouter 将LLM的选择构建为基于“任务-查询-模型”图的归纳边预测,从而实现成本效益评估并轻松集成新的LLM。为了明确地平衡性能和成本,FrugalGPT 采用了LLM级联方法,而FORC 将查询路由到适当大小的模型,以实现经济高效的推理。TO-Router 将多个领域特定的专家 LLM 统一在一个界面下,并根据任务需求调度查询。C2MAB-V 利用成本感知的组合多臂老虎机来动态选择最佳的LLM子集。 RouterDC 通过查询和 LLM 嵌入之间的双重对比学习来增强路由。最后,RouteLLM 利用人类偏好数据在强 LLM 和弱 LLM 之间进行动态选择,从而在保持质量的同时有效降低成本。
与以往方法不同,Router-R1 将路由视为一个顺序决策过程,将内部“思考”步骤与多轮模型路由交织在一起,通过将路由器本身实例化为一个功能强大的 LLM 来优化其答案。此外,其基于强化学习的训练利用成本奖赏来平衡性能和成本,从而实现灵活的性能与成本权衡以及资源感知路由。
2.2 Optimizing LLM Behaviors via Reinforcement Learning
近年来,强化学习 (RL) 已成为一种强大的范式,可用于微调大语言模型 (LLM),使其更好地契合人类偏好。早期的研究,例如 RLHF(基于人类反馈的强化学习),首先基于人类判断训练奖赏模型,然后应用策略优化算法(例如 PPO)来引导基础语言模型获得更理想的输出。在此基础上,RLAIF 在摘要和对话等任务上表现出相当甚至更优的性能,其直接变体 (d-RLAIF) 无需显式奖赏模型,从而提高了效率。RRHF 对模型生成的响应和外部响应进行排序,以在没有奖励预测器的情况下训练偏好,取得了与 RLHF 相当的效果。最近,直接偏好优化 (DPO) 系列方法更进一步,直接基于人类偏好数据进行训练,避免了 RL 采样和复杂的调优,同时性能与 RLHF 相当甚至更胜一筹。除了奖励驱动微调方面的这些进步之外,其他基于强化学习的技术,例如 Search-R1 ,也使 LLM 能够自适应地与搜索引擎等外部工具交互,从而在推理过程中动态检索和整合外部信息。这些方法凸显了强化学习在优化 LLM 行为方面的潜力,超越了基于静态提示的生成,尤其是在需要实时信息访问和决策的任务中。
3.Router-R1
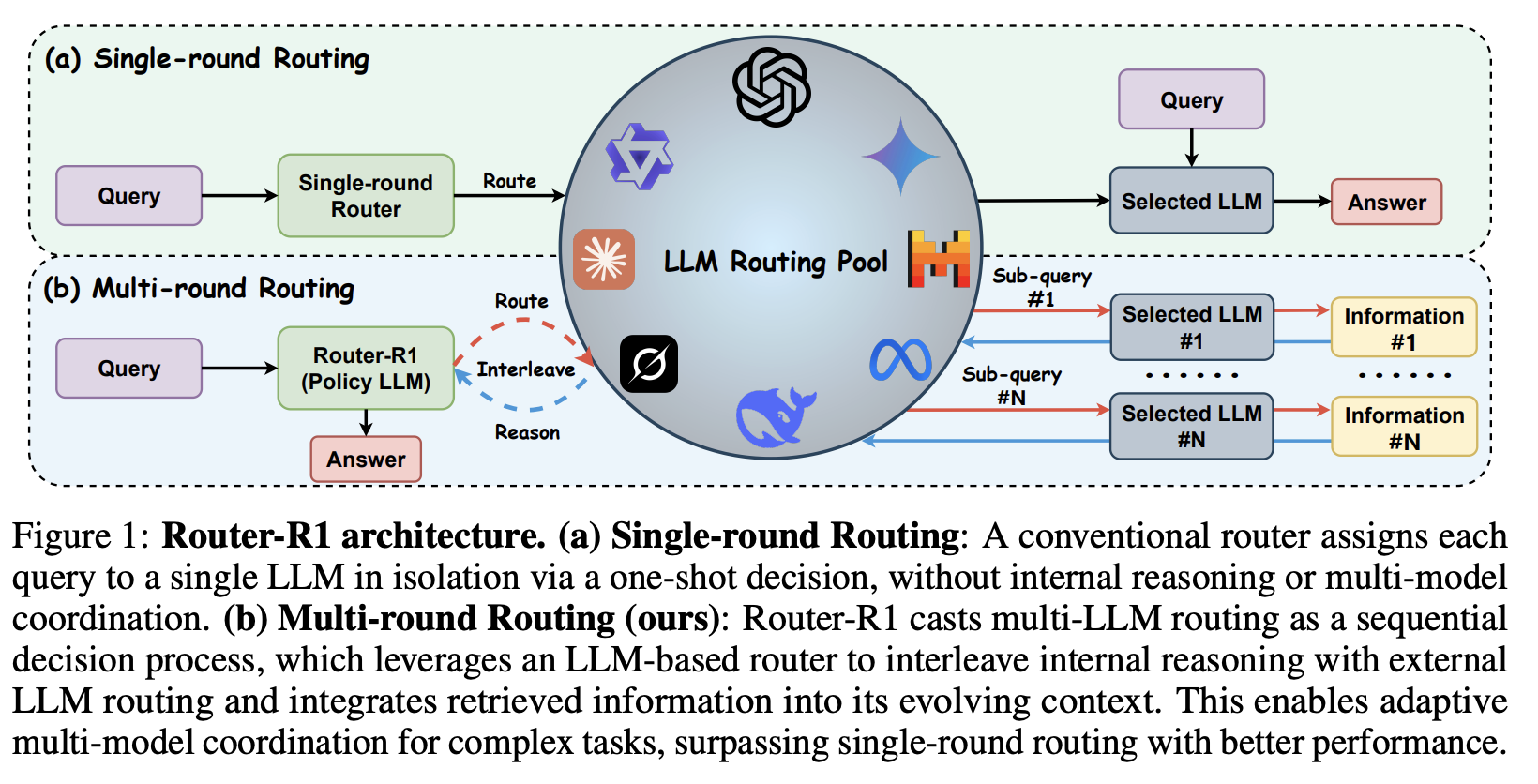
在本节中,我们将我们提出的 Router-R1 分为三个部分进行详细介绍。第 3.1 节介绍了基于 LLM 路由池的强化学习公式。第 3.2 节介绍了奖赏设计,其中包括格式奖赏、最终结果奖赏和成本奖赏。第 3.3 节描述了多轮交互训练过程,包括训练提示模板和与 LLM 路由池的多轮交互。图 1 展示了 Router-R1 的架构。
3.1 Reinforcement Learning via Coordination with a LLM Routing Pool
在 Router-R1 中,我们采用通用策略优化目标,其中 LLM 路由池 形式化如下所示:
其中 表示待优化的策略 LLM, 是参考 LLM,可以对其进行固定或迭代更新以实现稳定训练。 表示来自数据集 的输入样本, 表示从策略 采样得到的生成输出,这些输出与访问 LLM 路由池 获得的结果交织在一起。 是奖赏函数,P 是 LLM 路由池,它提供了一组可供选择的候选 LLM。KL 正则化项确保更新后的策略保持接近参考值,正则化系数 控制这种权衡。该公式具有通用性,涵盖各种正则化强化学习算法,例如 PPO、GRPO 和 KL 约束方法,从而允许对 LLM 候选池进行灵活的策略更新。
此外,在该优化目标下,策略 LLM 能够从LLM路由池 中动态地多轮选择一个候选 LLM,并通过为候选 LLM 提供相关上下文信息来获取关于输入样本的辅助信息,从而增强策略LLM的推理过程。此时,策略LLM可以被视为一个协调器,选择并协调多个候选LLM,共同解决复杂任务。
3.2 Reward Curation
为了给 Router-R1 提供合理有效的监督信号,我们精心设计了奖赏函数,包括格式奖赏、最终结果奖赏和成本奖赏,下面我们将详细描述。
3.2.1 Format Rewards
受 [8] 的启发,为了稳定训练并确保 LLM 响应符合预定义格式(详见下文 3.3 节),我们对 Router-R1 实施了严格的格式验证。具体来说,格式奖赏根据以下规则分配:如果响应不满足所需格式,则格式奖励设置为 -1;否则,设置为 0:
3.2.2 Final Outcome Rewards
在 Router-R1 中,我们采用精确匹配(EM)来衡量 LLM 预测答案与 ground truth 的正确性,并将其作为唯一的最终结果奖赏来指导 Router-R1 的优化:
其中 是从生成输出 中提取的预测答案, 表示基本事实。EM 强调预测答案与标准答案的完全且严格匹配,许多研究已证明它是一种简洁有效的基于规则的奖赏。
3.2.3 Cost Rewards
为了平衡从路由池中调用候选 LLM 的额外成本,我们引入了查询候选 LLM 所产生的计算成本作为成本奖赏。这种设计使得 Router-R1 不仅能够优化模型性能,还能在性能和计算效率之间取得平衡。
形式上,成本奖赏与候选 LLM 产生的输出 token 数量以及依赖模型的每个 token 成本函数成反比,这反映了使用不同模型的计算成本:
其中 表示所选候选 LLM 的参数数量, 表示其生成的输出 token 数量。 是一个预定义的成本函数,它将模型大小映射到每个 token 的计算成本(例如,基于 LLM API 服务的定价等级)。需要注意的是,成本奖赏在训练期间将被标准化为 0 到 1 之间。
这样,模型规模越大,输出的token越多,成本奖赏越小,从而为Router-R1提供了实现性能与成本平衡的能力。
3.2.4 Overall Rewards
综上所述,Router-R1的整体奖赏函数可以定义为:
其中 是控制模型性能和成本之间平衡的超参数。
具体来说,为了缓解奖赏黑客攻击并提高优化稳定性,我们引入了分层奖赏机制,以改进整体奖赏函数(为简洁起见,公式 5 中未显示)。在 Router-R1 中,三个奖赏组件被赋予不同的优先级,在公式 5 中从左到右依次递减。具体而言,如果格式奖励为 -1,则其余两个奖赏将被无效(设置为零),无论其原始值如何。这种分层设计在优化性能或计算效率之前强制执行关键约束,从而有助于 Router-R1 的稳定可靠训练。
在我们的实验中,如此清晰的基于规则的奖赏组合足以很好地优化Router-R1,这也证明了我们的奖赏函数设计的合理性和有效性。
3.3 Multi-Round Interaction Training Paradigm
在本节中,我们描述了 Router-R1 的训练提示模板以及与 LLM 路由池的多轮交互。
3.3.1 Training Prompt Template

受 [8, 13] 的启发,我们为 Router-R1 构建了如图 2 所示的训练提示模板。为了确保响应准确且合理,我们采用了一种结合内部推理和选择性外部 query 的结构化提示。收到问题后,Router-R1 首先在 <think> 和 </think> 块内执行内部分析,以评估是否需要更多信息。如果需要,它会根据预定义的 LLM 路由池和模型描述(包括参数大小和任务专业化等详细信息,我们将在附录 C 中详细说明)通过 <search> Candidate LLM: Query </search> 查询合适的专用 LLM。检索到的信息在 <info> 和 </info> 标签内返回,并且该过程可能会迭代以收集补充见解。最终答案在 <answer> 和 </answer> 块内输出。
值得注意的是,此处的模型描述仅作为每个候选 LLM 的初始先验。在策略优化过程中,策略 LLM 通过交互和反馈自适应地学习每个候选 LLM 的优势和劣势。为了进一步增强适应性,提示设计还支持无缝集成新的候选 LLM,而无需重新训练。具体而言,Router-R1 可以通过将新添加的 LLM 的描述直接合并到提示中来实现这种泛化能力。这种灵活性使 Router-R1 能够动态扩展其路由池,并有效适应新 LLM 的快速涌现。
3.3.2 Multi-Round Interaction with a LLM Routing Pool
根据图 2 中的提示,Router-R1 首先分析输入问题以识别必要信息,然后从路由池中选择最合适的候选 LLM,通过子问题进行查询。在训练过程中,它会学习分解复杂查询,并根据不同 LLM 的优势进行自适应路由。
每当生成的序列中出现一个特殊的 <search> 标签,指定目标 LLM 和预期的子查询时,就会触发路由过程。检测到后,Router-R1 会查询指定的 LLM,并将其响应重新插入序列中以继续推理(为确保训练稳定,带有 <info> 标签的外部响应不参与损失计算)。对于复杂任务,Router-R1 可以执行多轮路由,迭代地整合来自多个来源的信息,最终得出最终答案。对于简单问题,Router-R1 可以仅依靠策略 LLM 的内部知识来生成答案,这展现了其判断是否需要外部信息的能力。